
来源:拿笔小星_ ,
blog.csdn.net/u013096088/article/details/83047282
这篇博客开始,我打算带大家去解读一下JVM平台下的字节码文件(熟悉而又陌生的感觉)。众所周知,Class文件包含了我们定义的类或接口的信息。然后字节码又会被JVM加载到内存中,供JVM使用。那么,类信息到了字节码文件里,它们如何表示的,以及在字节码里是怎么分布的呢?带着这些问题,让我们去深入了解字节码文件吧。
Class文件的结构
Class文件是一组以8位字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在Class文件之中,中间没有添加任何分隔符,这使得整个Class文件中存储的内容几乎全部是程序运行的必要数据,没有空隙存在。当遇到需要占用8位字节以上空间地数据项时,则会按照高位在前的方式分割成若干个8位字节进行存储。
每一个 Class 文件对应于一个如下所示的 ClassFile 结构体。
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
这种数据结构,类似C语言结构体。这个结构体中只有两种数据类型:无符号数和表,后面的解析都要以这两种数据类型为基础,所以这里要先介绍这两个概念。
无符号数属于基本的数据类型,以u1,u2,u4,u8来分别代表1个字节,2个字节,4个字节和8个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以“_info”结尾。表用于描述有层次关系的复合结构的数据,整个Class文件本质就是一张表。
下面是我的案例代码,本章将以此代码生成的字节码文件作为例子来分析。
public class MyTest2 {
String str = "Welcome";
private int x = 5;
public static Integer in = 10;
public static void main(String[] args) {
MyTest2 myTest2 = new MyTest2();
myTest2.setX(8);
in = 20;
}
public void setX(int x) {
this.x = x;
}
}
对应生成的字节码文件格式如下:(数据内容较多,只是截了部分)

上面的数字是以16进制表示的。我们可以按照之前的结构一项项去解读它。
Class文件解析
magic
魔数,u4类型的数据,占4个字节。魔数的唯一作用是确定这个文件是否为一个能被虚拟机所接受的 Class 文件。魔数值固定为 0xCAFEBABE(咖啡宝贝),不会改变。
minor_version、major_version
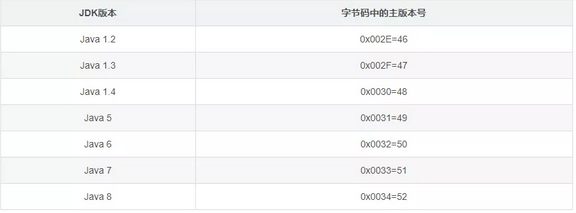
紧接着魔数之后的4个字节为Java版本信息:第5和第6个字节是次版本号(minor_version),第7和第8个字节是主版本号(major_version)。
就看当前这个字节码,次版本号是0×0000=0,主版本号是0×0034=52。我本地机器用的是JDK1.8,所以可生成的Class文件主版本号最大值为52.0。
下面给出了Java各个主版本号,以供参考。
constant_pool_count
常量池计数器,u2类型的数据。它是常量池的入口,表示紧跟着它后面的常量池的元素个数。算一下,0x002F=47,即常量池里的元素有47个。这里我用jdk的内置工具javap,反编译一下,可以输出常量池的信息以及元素个数。执行命令:javap -verbose。输出结果如下:
Constant pool:
#1 = Methodref #10.#34 // java/lang/Object."<init>":()V
#2 = String #35 // Welcome
#3 = Fieldref #5.#36 // com/shengsiyuan/jvm/bytecode/MyTest2.str:Ljava/lang/String;
#4 = Fieldref #5.#37 // com/shengsiyuan/jvm/bytecode/MyTest2.x:I
#5 = Class #38 // com/shengsiyuan/jvm/bytecode/MyTest2
#6 = Methodref #5.#34 // com/shengsiyuan/jvm/bytecode/MyTest2."<init>":()V
#7 = Methodref #5.#39 // com/shengsiyuan/jvm/bytecode/MyTest2.setX:(I)V
#8 = Methodref #40.#41 // java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
#9 = Fieldref #5.#42 // com/shengsiyuan/jvm/bytecode/MyTest2.in:Ljava/lang/Integer;
#10 = Class #43 // java/lang/Object
#11 = Utf8 str
#12 = Utf8 Ljava/lang/String;
#13 = Utf8 x
#14 = Utf8 I
#15 = Utf8 in
#16 = Utf8 Ljava/lang/Integer;
#17 = Utf8 <init>
#18 = Utf8 ()V
#19 = Utf8 Code
#20 = Utf8 LineNumberTable
#21 = Utf8 LocalVariableTable
#22 = Utf8 this
#23 = Utf8 Lcom/shengsiyuan/jvm/bytecode/MyTest2;
#24 = Utf8 main
#25 = Utf8 ([Ljava/lang/String;)V
#26 = Utf8 args
#27 = Utf8 [Ljava/lang/String;
#28 = Utf8 myTest2
#29 = Utf8 setX
#30 = Utf8 (I)V
#31 = Utf8 <clinit>
#32 = Utf8 SourceFile
#33 = Utf8 MyTest2.java
#34 = NameAndType #17:#18 // "<init>":()V
#35 = Utf8 Welcome
#36 = NameAndType #11:#12 // str:Ljava/lang/String;
#37 = NameAndType #13:#14 // x:I
#38 = Utf8 com/shengsiyuan/jvm/bytecode/MyTest2
#39 = NameAndType #29:#30 // setX:(I)V
#40 = Class #44 // java/lang/Integer
#41 = NameAndType #45:#46 // valueOf:(I)Ljava/lang/Integer;
#42 = NameAndType #15:#16 // in:Ljava/lang/Integer;
#43 = Utf8 java/lang/Object
#44 = Utf8 java/lang/Integer
#45 = Utf8 valueOf
#46 = Utf8 (I)Ljava/lang/Integer;
可是,我们得到的常量池里的元素个数是46。我们看常量池第一个元素,它的索引是从1开始的。所以索引值范围是1~46。设计者将第0项常量空出来是有特殊考虑的,这样做的目的在于满足后面某些指向常量池的索引值的数据在特定情况下需要表达“不引用任何一个常量池项目”的含义,这种情况就可以把索引值置为0来表示。根本原因在于,索引为0也是一个常量(保留常量),只不过它不位于常量表中。这个常量就对应Null值,所以常量池的索引从1而非0开始。
常量池结构剖析
紧接其后的就是常量池了。一个Java类中定义的很多信息都是由常量池维护和描述的。可以将常量池看作是Class文件的资源库。比如:Java类中定义的方法与变量信息,都是存储在常量池中。常量池中主要存储两类常量:字面常量和符号引用。字面量,如文本字符串,Java中声明为常量值,而符号引用如类和接口的全局限定名,字段的名称和描述符,方法的名称和描述符等。
注:常量池中存储的不一定是不变的量!如,private int x = 5,x是变量,但“x”这个变量名字依然存在常量池中。
我们也可以把常量池当做一个数组(常量池中的每一项常量都是一个表),与一般数组不同的是,常量池数组中不同的元素类型,结构都是不同的,长度当然也不相同;但是每一个元素的第一个数据都是u1类型,该字节是个标志位,占一个字节。JVM在解析长量池时,会根据这个u1类型来获取元素的具体类型。目前,常量池中出现的常量类型有14种,如下表:
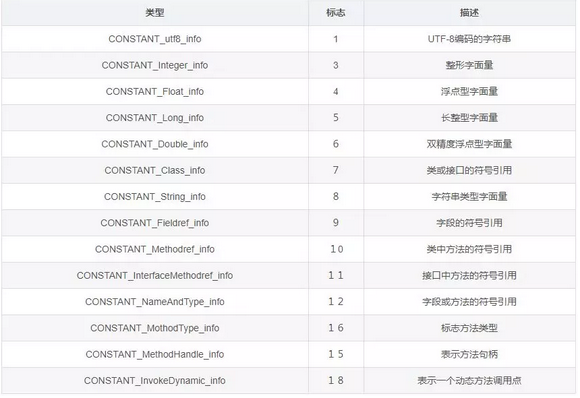
有了这张表就可以继续剖析常量池的内容了,常量池第一个字节就是一个标志位,0x000A=10,说明第一个常量类型是CONSTANT_Methodref_info。这是一个表类型,它对应的结构是:
CONSTANT_Methodref_info {
u1 tag;
u2 class_index;
u2 name_and_type_index;
}
可知,该类型常量占1+2+2=5个字节。所以我们从常量池前5个字节就是第一个常量元素了。紧接后面就是第二个常量,同样的,开始是一个标志位,即0x008=8。可知,第二个常量是CONSTANT_String_info类型。CONSTANT_String_info 用于表示java.lang.String类型的常量对象,格式如下:
CONSTANT_String_info {
u1 tag;
u2 string_index;
}
所以常量池的第二个元素占3个字节。按照这个套路,我们就可以找出每一个常量了。一直数到第46个常量,常量池就结束了。此处是常量池中的14种常量项的结构总表。感兴趣的可以对照这个表,去把剩下的常量对照出来。
常量项分析
第一个常量是CONSTANT_Methodref_info类型的,它描述了类中方法的符号引用。class_index 项的值必须是对常量池的有效索引,常量池在该索引处的项必须是CONSTANT_Class_info结构,表示一个类或接口。
class_index表示的索引值是0x000A=10。根据之前 javap -verbose 输出的常量池信息,我们可以知道常量池的#10项是CONSTANT_Class_info类型的常量。该类型常量用于表示类或接口,格式如下:
CONSTANT_Class_info {
u1 tag;
u2 name_index;
}
name_index 项的值,必须是对常量池的一个有效索引。常量池在该索引处的项必须是CONSTANT_Utf8_info结构,代表一个有效的类或接口二进制名称的内部形式。
name_index 表示的索引值是43(这里我直接从上面的量池信息读出,如果从字节码里看,此处的值为0x002B=43)。所以接着找常量池第43项的常量类型,是CONSTANT_utf8_info类型,用于表示字符串常量的值,结构如下:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
其中,length 项的值指明了 bytes[]数组的长度,bytes[]是表示字符串值的byte数组。在这里,我把字节码常量池中#43处常量的16进制值单独拿出来来看。下图有背景色的部分就是完整的CONSTANT_Utf8_info类型常量表示。

第一个字节是标志位,0×0001=1。说明此常量类型是CONSTANT_Utf8_info。后面2个字节是0×0010=16,表示后面bytes[]长度为16。所以往后数16个字节就是整个它表示的字符串常量。
bytes[]第一个字节值,0x006A。根据 ASCII码对照表,代表的字符串是”j”。依次的,第二个字节0×0061,代表“a”,等等。把16个字节看完你就得到了字符串常量表示“java/lang/Object”。好了这表示一个类的全限定名。饶了一大圈,终于找到最终要表示的常量信息了。
到此,我们把第一个常量的结构中的class_index就解析完了,还剩一个name_and_type_index。它表示了常量池在该索引处的项必须是 CONSTANT_NameAndType_info结构,它表示当前字段或方法的名字和描述符。后面大家可以根据常量池中的14种常量项的结构总表,并结合javap得到的常量池信息,自己去分析每个常量在常量池里是怎么个回事。
总结
这篇文章介绍了,字节码文件的结构组成,并分析了魔数、次主版本号和常量池。尤其带大家深入分析了常量池的组成结构,并拿例子中的常量池第一个常量作为案例,完整解析它在常量池中的各项引用。套路都是一样的,常量池后面的常量,大家可以自己去分析了。你会发现类中有用的信息都存在了我们的常量池里,然后以索引的形式,给代码使用。这也就是常量池作为class文件的资源仓库的原因了。